40行Python代码实现天气预报和每日鸡汤推送功能
这篇文章主要介绍了通过40行Python代码实现天气预报和每日鸡汤推送功能,代码简单易懂,非常不错具有一定的参考借鉴价值 ,需要的朋友可以参考下
好东西要学会分享,因此小编打算分三个步骤来教大家实现,最后会给出源代码。
第一步,实现爬取爱词霸网站的每日一句: 爱词霸的每日一句包括了英文版和中文版。爬取下来实际上4行有效代码就能搞定,不过为了提高代码的重用性,就将这个功能封装成了一个函数,以后需要时候用一行代码调用它便行了。下面贴出第一步的源代码,注释写得很详细了,有不懂的可以在文章下面提问哦。
# 小技巧:pycharm中,alt+enter快捷键可快速安装缺失库
import json
import requests
# 爬取爱词霸每日鸡汤
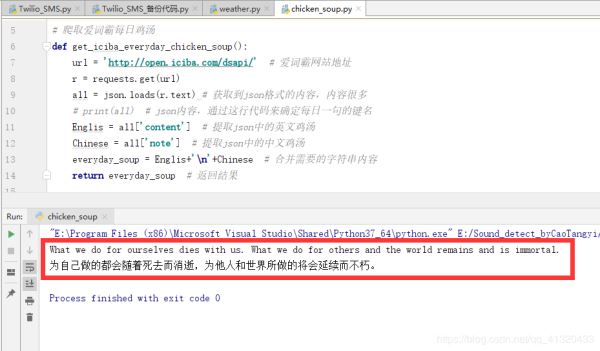
def get_iciba_everyday_chicken_soup():
url = 'http://open.iciba.com/dsapi/' # 词霸免费开放的jsonAPI接口
r = requests.get(url)
all = json.loads(r.text) # 获取到json格式的内容,内容很多
# print(all) # json内容,通过这行代码来确定每日一句的键名
Englis = all['content'] # 提取json中的英文鸡汤
Chinese = all['note'] # 提取json中的中文鸡汤
everyday_soup = Englis+'\n'+Chinese # 合并需要的字符串内容
return everyday_soup # 返回结果
print(get_iciba_everyday_chicken_soup())上面代码执行结果截图如下:成功爬取每日鸡汤,第一步实现。
第二步,爬取天气预报网站的天气情况!
需要爬取的是天气网站的数据:http://www.tianqi.com/ 实现这个功能的所有代码也封装在了一个函数里面了,其实有效代码不到20行。调用函数的时候传入的参数改为对应城市的拼音就可。
import urllib.request # 需要安装 urllib 库
from bs4 import BeautifulSoup #需要安装 bs4 库
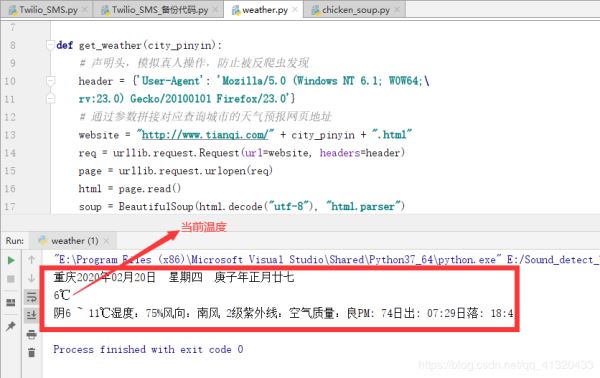
def get_weather(city_pinyin):
# 声明头,模拟真人操作,防止被反爬虫发现
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64;\
rv:23.0) Gecko/20100101 Firefox/23.0'}
# 通过传入的城市名拼音参数来拼接出该城市的天气预报的网页地址
website = "http://www.tianqi.com/" + city_pinyin + ".html"
req = urllib.request.Request(url=website, headers=header)
page = urllib.request.urlopen(req)
html = page.read()
soup = BeautifulSoup(html.decode("utf-8"), "html.parser")
# html.parser表示解析使用的解析器
nodes = soup.find_all('dd')
tody_weather = ""
for node in nodes: # 遍历获取各项数据
temp = node.get_text()
if (temp.find('[切换城市]')):
temp = temp[:temp.find('[切换城市]')]
tody_weather += temp
# 去除字符串中的空行:
tianqi = "".join([s for s in tody_weather.splitlines(True)
if s.strip()])
return tianqi # 返回结果
# 调用封装号好的函数获取天气预报,参数‘chongqing'是重庆的拼音:
print(get_weather('chongqing'))
# 想查询哪个城市的天气情况,直接将参数替换为它的拼音即可上面代码执行结果截图如下: