
UnicodeDecodeError解决链接:UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0x80 in position 167: illegal multibyte sequence
1. 问题1
1.1 问题是什么?
在使用 pyminifier 加密代码时,输入如下指代
C:\Users\54867>pyminifier --nonlatin --replacement-length=10 -O demo01.py报如下错误
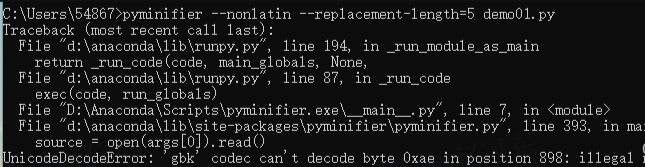
根据错误提示:意思是 pyminifier.py 脚本代码需要修改,某行需要加上 encoding=‘utf-8’。
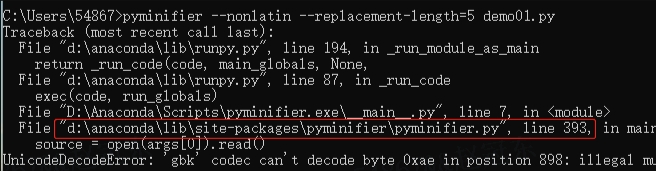
1.2 如何解决的?
找到 pyminifier.py 文件,修改出错代码
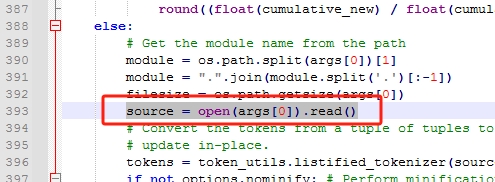
source = open(args[0]).read()
改为
source = open(args[0],encoding='utf-8').read()
再执行代码
C:\Users\54867>pyminifier --nonlatin --replacement-length=10 -O demo01.py
2. 读数据问题
问题描述:
data = pd.read_table(
file_path + '\\' + '{}.txt'.format(txt_name),
index_col=False, encoding='latin1', skiprows=12, sep=',', error_bad_lines=False, nrows=None)错误信息:
Traceback (most recent call last):
File "D:\Anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3418, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-4-dc331af0451b>", line 1, in <module>
data = pd.read_table(
File "D:\Anaconda\lib\site-packages\pandas\io\parsers\c_parser_wrapper.py", line 75, in __init__
self._reader = parsers.TextReader(src, **kwds)
File "pandas\_libs\parsers.pyx", line 544, in pandas._libs.parsers.TextReader.__cinit__
File "pandas\_libs\parsers.pyx", line 633, in pandas._libs.parsers.TextReader._get_header
File "pandas\_libs\parsers.pyx", line 847, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas\_libs\parsers.pyx", line 1952, in pandas._libs.parsers.raise_parser_error
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb0 in position 65: illegal multibyte sequence2.1 问题分析
这个错误信息表明在读取文件时,Python 的 Pandas 库遇到了字符编码问题。具体来说,UnicodeDecodeError 表示文件中存在无法用指定编码(在这个情况下是 gbk)解码的字符。
解决步骤
1.检查文件编码:
确认你要读取的文件的编码格式。常见的编码格式有 utf-8、latin1 和 gbk 等。如果不确定,可以使用文本编辑器(如 Notepad++)打开文件并查看编码。
2.指定正确的编码:
在使用 pd.read_table() 时,添加 encoding 参数来指定正确的编码。例如,如果文件是 utf-8 编码,可以这样修改代码:
data = pd.read_table('your_file_path.txt', encoding='utf-8')如果文件是 latin1 编码,可以使用:
data = pd.read_table('your_file_path.txt', encoding='latin1')3.使用 errors 参数:
如果你希望忽略无法解码的字符,可以使用 errors='ignore' 或 errors='replace' 参数:
data = pd.read_table('your_file_path.txt', encoding='gbk', errors='ignore')使用 errors='ignore' 会跳过无法解码的字符,而 errors='replace' 会用替代字符(如 ?)替换这些字符。
4.尝试其他读取函数:
如果文件是 CSV 格式,可以尝试使用 pd.read_csv(),并同样指定编码:
data = pd.read_csv('your_file_path.csv', encoding='utf-8')示例代码
import pandas as pd
# 尝试不同的编码
try:
data = pd.read_table('your_file_path.txt', encoding='utf-8')
except UnicodeDecodeError:
data = pd.read_table('your_file_path.txt', encoding='latin1')
# 或者使用错误处理
data = pd.read_table('your_file_path.txt', encoding='gbk', errors='replace')总结
通过确认文件编码并在读取时指定正确的编码,可以解决 UnicodeDecodeError 问题。如果仍然无法解决,请检查文件内容,确保没有损坏或意外的字符。
2.2 解决办法
使用latin1将问题解决。
data = pd.read_table('your_file_path.txt', encoding='latin1')2.3 Latin-1介绍
Latin-1(也称为 ISO-8859-1)是一种单字节字符编码,主要用于表示西欧语言中的字符。它是 ISO 8859 系列的一部分,具体的特点如下:
特点
1.字符范围:
Latin-1 可以表示 256 个字符(从 0 到 255),其中包括:
控制字符(0-31)
常见的英文字母(大写和小写)
数字(0-9)
标点符号
一些特殊字符,如法语、德语、西班牙语等语言中的字符(例如 é, ñ, ü 等)。
2.兼容性:
Latin-1 是 ASCII 的超集,因此 ASCII 字符(0-127)在 Latin-1 中的表示方式是相同的。
3.使用场景:
Latin-1 主要用于西欧语言的文本文件,特别是在早期的网页和电子邮件中常见。
它在某些情况下被用作数据交换格式,尤其是在不需要支持更广泛字符集的应用中。
4.局限性:
Latin-1 无法表示所有语言的字符,例如中文、阿拉伯文、俄文等。
对于需要更广泛字符集的应用,通常推荐使用 UTF-8 编码。
示例
在 Python 中,使用 Latin-1 编码读取文件的示例:
import pandas as pd
# 以 Latin-1 编码读取文件
data = pd.read_csv('your_file_path.csv', encoding='latin1')

